Magi:Comics to Text and Generating Scripts
Magi revolutionizes comic accessibility by automatically transcribing visual content into text-based scripts, enhancing inclusivity and engagement

In the realm of comic books, the visually immersive experience has been a barrier for individuals with visual impairments. Magi, developed by the Visual Geometry Group at the University of Oxford, aims to break down this barrier by automatically transcribing comics into text and generating scripts.
What is Magi?
Magi is a unified model designed to detect panels, text boxes, and character boxes in manga pages. It clusters characters by identity and associates dialogues with their respective speakers.
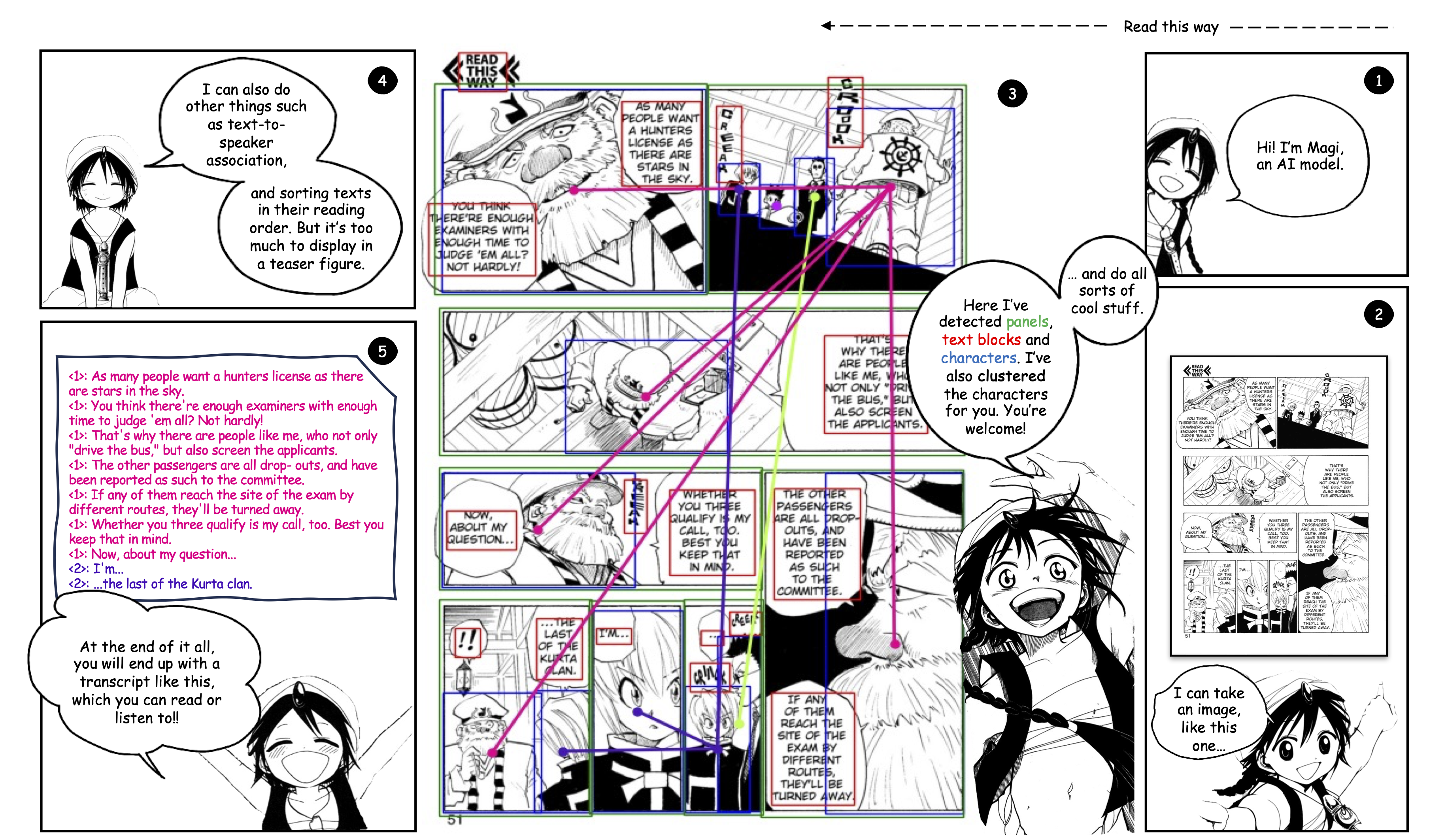
How Does it Work?
Panel Detection: Identifies individual panels on manga pages, forming the basis for understanding the comic layout.
Text Block Detection: Recognizes text blocks within panels, typically containing dialogues or narrative text.
Character Detection: Identifies character images on the page, crucial for associating text with speaking characters.
Character Clustering: Clusters detected characters by their identities to distinguish different characters on the page.
Text-to-Speaker Association: Determines which character utters each text block, essential for generating accurate scripts.
Reading Order Sorting: Sorts detected text blocks according to the reading order of the comic to ensure narrative coherence.

Usage
from transformers import AutoModel
import numpy as np
from PIL import Image
import torch
import os
images = [
"path_to_image1.jpg",
"path_to_image2.png",
]
def read_image_as_np_array(image_path):
with open(image_path, "rb") as file:
image = Image.open(file).convert("L").convert("RGB")
image = np.array(image)
return image
images = [read_image_as_np_array(image) for image in images]
model = AutoModel.from_pretrained("ragavsachdeva/magi", trust_remote_code=True).cuda()
with torch.no_grad():
results = model.predict_detections_and_associations(images)
text_bboxes_for_all_images = [x["texts"] for x in results]
ocr_results = model.predict_ocr(images, text_bboxes_for_all_images)
for i in range(len(images)):
model.visualise_single_image_prediction(images[i], results[i], filename=f"image_{i}.png")
model.generate_transcript_for_single_image(results[i], ocr_results[i], filename=f"transcript_{i}.txt")
Why Use Magi?
Accessibility: Enables individuals with visual impairments to engage with comics through text-based content.
Efficiency: Automates the transcription process, saving time for comic creators and publishers.
Accuracy: Provides a detailed script with dialogue attribution, enhancing the reader's understanding of the narrative.

Conclusion
Magi revolutionizes the accessibility of comics by automatically transcribing visual content into text-based scripts. With its unified model and robust features, Magi paves the way for a more inclusive and engaging comic reading experience for all.